LLM-CLIP
CLIP
模型结构
CLIP 「Contrastive Language-Image Pretraining」是一个多模态模型,能够同时理解和生成图像和文本。它可以将图像和文本进行对比学习,从而在各种多模态任务中表现出色。
CLIP需要的数据为图像及其描述,数据集中大约包含4亿张图像及其描述。CLIP整体模型如下所示:
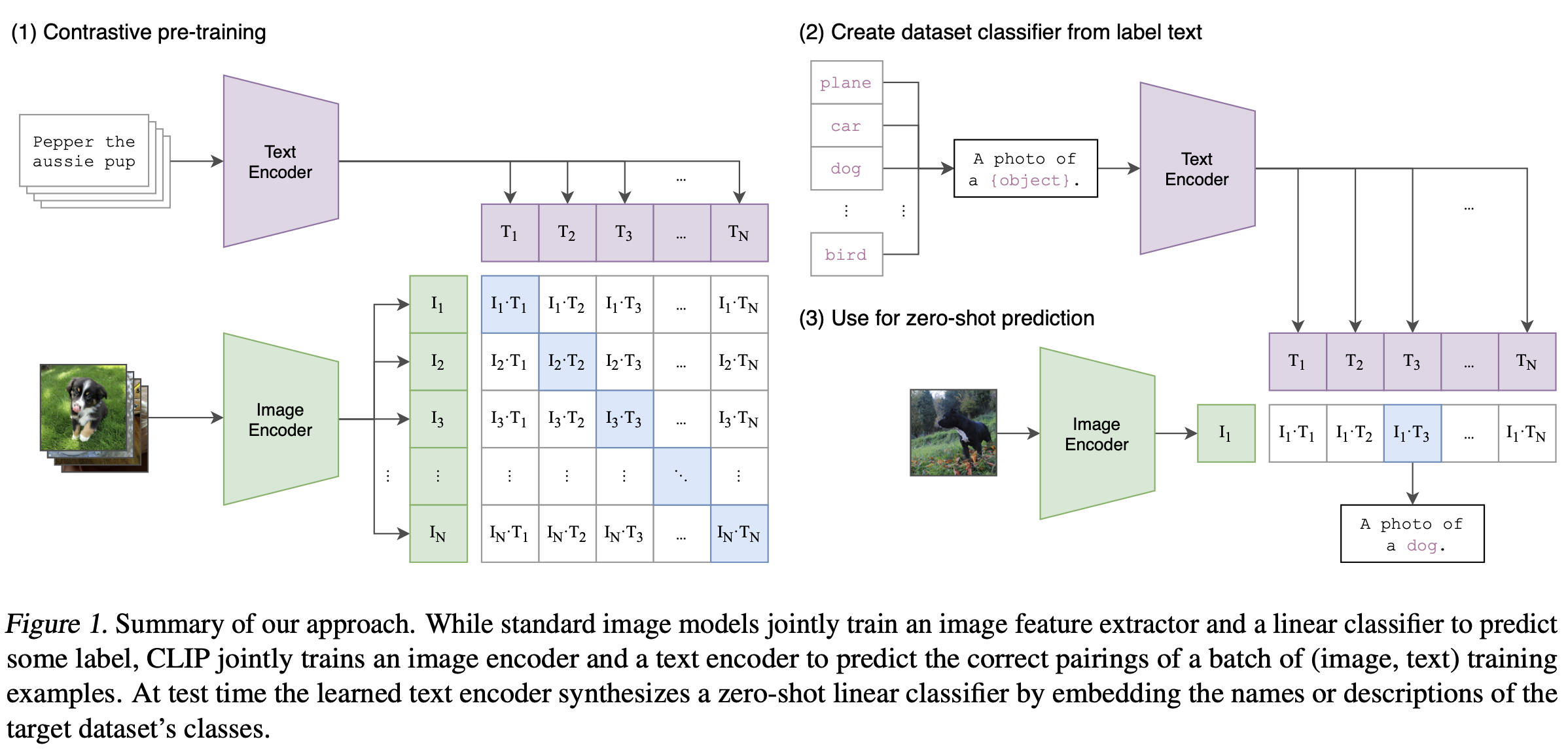
(1). 对比预训练 「Contrastive pre-training」
CLIP 是图像编码器和文本编码器的组合,使用两个编码器对数据分别进行编码。然后使用余弦距离比较结果嵌入,刚开始训练时,即使文本描述与图像是相匹配的,它们之间的相似性肯定也是很低的。随着模型的不断更新,在整个数据集中重复该过程,编码器对图像和文本编码得到的嵌入会逐渐相似。
(2). 从标签文本创建数据集分类器 「Create dataset classifier from label text」
作用:
构建分类器:在传统的图像分类任务中,通常需要为每个类别训练一个专门的分类器。CLIP 通过文本编码器将标签转换为描述性文本,并进一步转换为特征向量,从而构建一个零样本分类器。这些特征向量可以看作是每个类别的“代表”,可以直接用于分类任务。
零样本学习:通过这种方式,CLIP 可以在没有看到任何特定类别的训练样本的情况下,依靠标签文本的描述来进行分类。这种能力被称为“零样本学习”,即模型可以识别从未见过的类别。
为什么需要这一步:
减少数据依赖:在实际应用中,获取每个类别的大量标注数据是非常困难的。通过从标签文本创建分类器,CLIP 能够在没有特定训练数据的情况下,利用现有的文本描述来实现分类。
提高模型泛化能力:传统分类器只能处理训练时见过的类别,而 CLIP 的这种方法使其能够处理新类别,提高模型的泛化能力和适用范围。
(3). 用于零样本预测 「Use for zero-shot prediction」
作用:
实际应用:在实际应用中,将待分类的图像输入图像编码器,得到图像的特征向量,然后将这个特征向量与之前生成的类别特征向量进行匹配,找到最接近的类别。这一过程就是零样本预测的核心。
扩展性:这一过程使得 CLIP 可以处理任意数量和类型的类别,只需提供相应的文本描述即可,无需重新训练模型。
为什么需要这一步:
实现分类任务:这一步是将 CLIP 应用于实际分类任务的关键,通过匹配图像和文本特征向量,实现图像分类。
灵活性和扩展性:这种方法使得模型可以处理新出现的类别和变化多端的任务,只需要相应的文本描述即可,无需重新训练。这大大提高了模型的灵活性和扩展性。