# 数组后面的数为排好序的数,一直交换直到把当前最大的数交换到最后 defbubble_sort(nums): n = len(nums) for i inrange(n): for j inrange(0:n-1-i): if nums[j] > nums[j+1]: # 交换 nums[j],num[j+1] = nums[j+1],nums[j] return nums
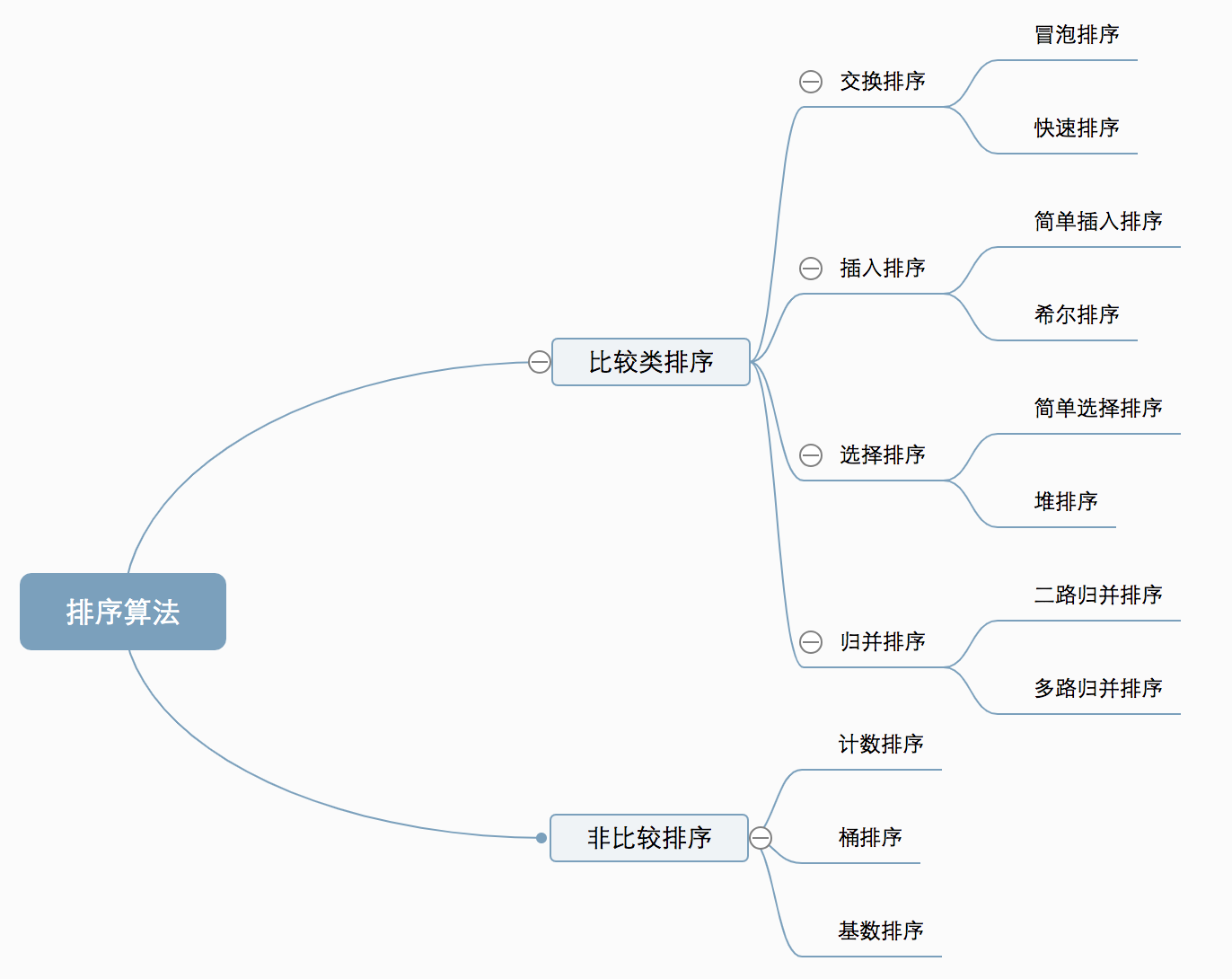
2.选择排序
3.插入排序
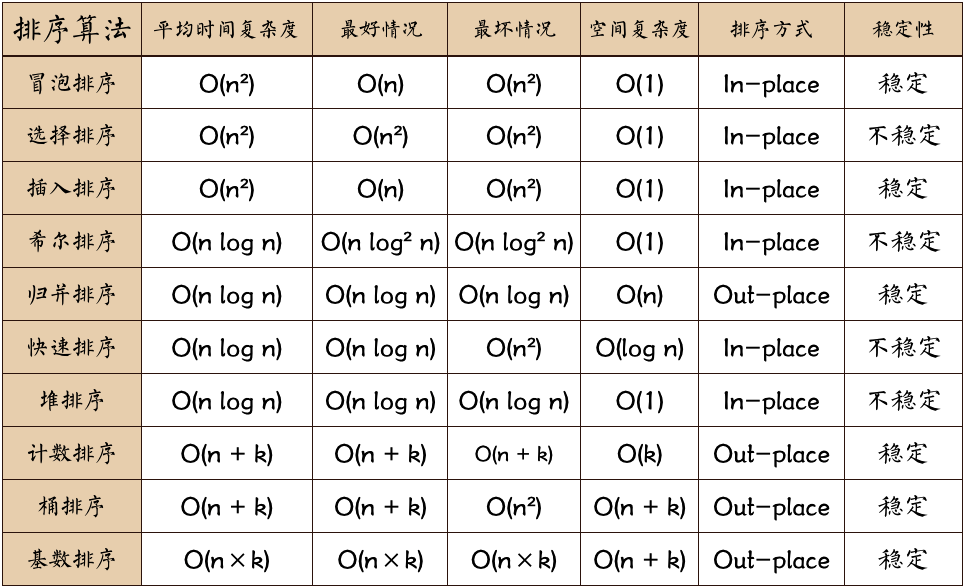
时间复杂度$O(N^2)$ 空间复杂度$O(1)$
1 2 3 4 5 6 7 8 9
# 数组前面的数为排好序的,每次在前面不断交换直到找到当前数的位置 definsertion_sort(nums): n = len(nums) for i inrange(1, n): j = i while j > 0and nums[j - 1] > nums[j]: nums[j], nums[j - 1] = nums[j - 1], nums[j] j -= 1 return nums
defquick_sort(nums): # 实现快排 iflen(nums) <= 1: return nums # 选取基准数 pivot = nums[len(nums)//2] # 实现分区 left = [x for x in nums if x < pivot] middle = [x for x in nums if x == pivot] right = [x for x in nums if x > pivot] # 将左右半区递归进行排序 return quick_sort(left) + middle + quick_sort(right)
defheapify(arr, n, i): whileTrue: largest = i # 初始化最大值为当前节点 left = 2 * i + 1# 左子节点 right = 2 * i + 2# 右子节点
# 如果左子节点存在且大于当前最大值,则更新最大值为左子节点 if left < n and arr[left] > arr[largest]: largest = left # 如果右子节点存在且大于当前最大值,则更新最大值为右子节点 if right < n and arr[right] > arr[largest]: largest = right # 如果最大值不是当前节点,则交换并继续调整子树 if largest != i: arr[i], arr[largest] = arr[largest], arr[i] i = largest else: break